Availability & Consistency
CAP THEOREM: an application can guarantee only two of the following features: Availability, Consistency, Partition Tolerance
Partition Tolerance: The system continues to operate despite arbitrary partitioning due to network failures. Networks aren’t reliable, so you’ll need to support partition tolerance. You’ll need to make a software tradeoff between consistency and availability. (essentially, every system is required to have some sort of fault tolerance. you have to be able to recover from network failures)
Availability: Every request receives a response, without guarantee that it contains the most recent version of the information. Every request received by an active node in the system must result in a response. In an available system, if our client sends a request to a server and the server has not crashed, then the server must eventually respond to the client. The server is not allowed to ignore the client’s requests.
A highly available system is where responses return the most readily available version of the data available on any node, which might not be the latest. It’s a good choice if the business needs allow for eventual consistency or when the system needs to continue working despite external errors.
Consistency: Every read receives the most recent write or an error.
-
Weak consistency: After a write, reads may or may not see it. A best effort approach is taken. i.e. if you are on a phone call and lose reception for a few seconds, when you regain connection you do not hear what was spoken during connection loss.
-
Eventual consistency: After a write, reads will eventually see it (typically within milliseconds). Data is replicated asynchronously. Eventual consistency works well in highly available systems. i.e. Email system, Search Engine Indexing, DNS.
-
Strong consistency: After a write, reads will see it. Data is replicated synchronously. Strong consistency works well in systems that need transactions. i.e. File System, Relational Database
Polling vs streaming
Polling: client checks with a server periodically (can be on a set schedule) to see if there are any new messages
-
a node sends a message to another node and then waits for a response
-
can be wasteful of resources if there are no new messages to retrieve, but it is simple to implement
-
can be inefficient if the receiving node is busy or there is high network latency
-
Polling is better for infrequent or low-priority messages, required need to conserve resources.
-
i.e. new email messages
Streaming: server pushes messages to the client as soon as they arrive
-
requires a little more setup than polling, but it can be more efficient: client doesn’t have to waste time checking for new messages when there are none
-
a node sends a continuous stream of messages to another node
-
sender does not need to wait for a response before sending the next message.
-
Streaming is better for high-frequency or high-priority messages, real-time updates or low tolerance for delays.
-
i.e. live video feed from a security camera, traffic updates, stock prices
Message Brokers and Messaging Patterns
Message Broker: software that enables applications, systems, and services to communicate with each other and exchange information. The message broker does this by translating messages between formal messaging protocols. This allows interdependent services to “talk” with one another directly, even if they were written in different languages or implemented on different platforms.
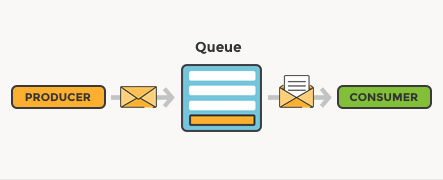
Message Queue: component that stores and orders the messages until the consuming applications can process them. In a message queue, messages are stored in the exact order in which they were transmitted and remain in the queue until receipt is confirmed.
Point-to-point messaging: This is the distribution pattern utilized in message queues with a one-to-one relationship between the message’s sender and receiver. Each message in the queue is sent to only one recipient and is consumed only once. Point-to-point messaging is called for when a message must be acted upon only one time. Examples of suitable use cases for this messaging style include payroll and financial transaction processing. In these systems, both senders and receivers need a guarantee that each payment will be sent once and once only.
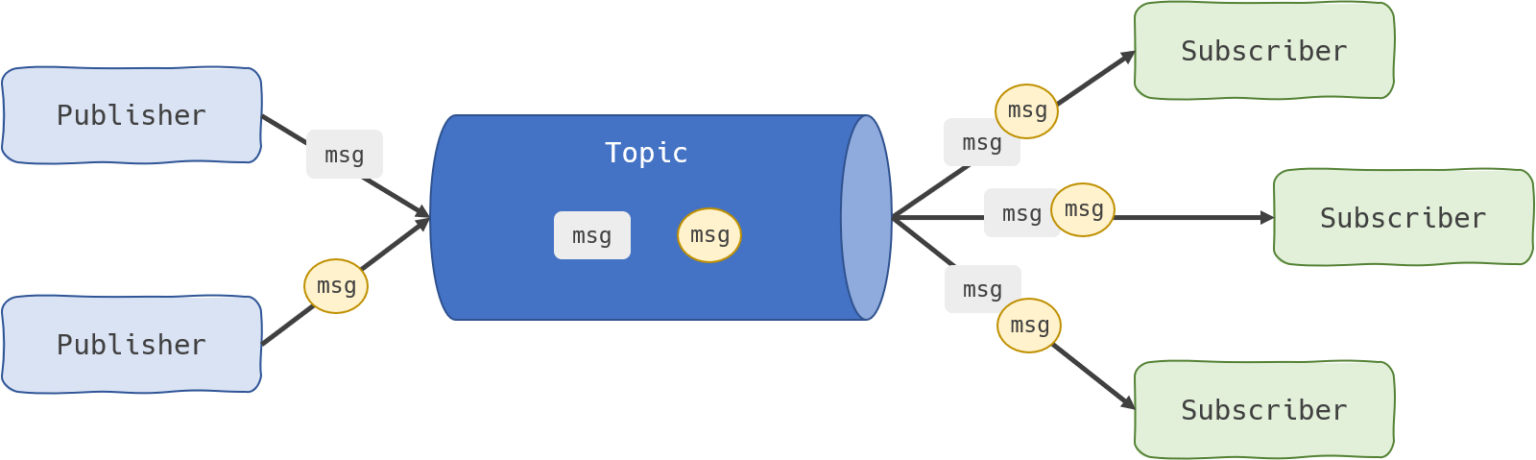
Publish/subscribe messaging: In this message distribution pattern, often referred to as “pub/sub,” the producer of each message publishes it to a topic, and multiple message consumers subscribe to topics from which they want to receive messages. All messages published to a topic are distributed to all the applications subscribed to it. This is a broadcast-style distribution method, in which there is a one-to-many relationship between the message’s publisher and its consumers. If, for example, an airline were to disseminate updates about the landing times or delay status of its flights, multiple parties could make use of the information: ground crews performing aircraft maintenance and refueling, baggage handlers, flight attendants and pilots preparing for the plane’s next trip, and the operators of visual displays notifying the public. A pub/sub messaging style would be appropriate for use in this scenario.
Event Streaming Platform: only offer pub/sub-style distribution patterns. Designed for use with high volumes of messages, event streaming platforms are readily scalable. They’re capable of ordering streams of records into categories called topics and storing them for a predetermined amount of time. Unlike message brokers, however, event streaming platforms cannot guarantee message delivery or track which consumers have received messages. Event streaming platforms offer more scalability than message brokers but fewer features that ensure fault tolerance (like message resending), as well as more limited message routing and queueing capabilities.
Asynchronism
Pre-computing: doing the time-consuming work in advance and serving the finished work with a low request time i.e. website pages built with a CMS are pre-rendered and locally stored as static HTML files on every change or running a script
Asynchronous Task Workflow: implementing a job queue that is checked by worker nodes, does the work, then send a notification to the frontend
A user comes to your website and starts a very computing intensive task which would take several minutes to finish. So the frontend of your website sends a job onto a job queue and immediately notifies the user: your job is in work, please continue to the browse the page. The job queue is constantly checked by a bunch of workers for new jobs. If there is a new job then the worker does the job and after some minutes sends a signal that the job was done. The frontend, which constantly checks for new “job is done” - signals, sees that the job was done and informs the user about it.
Benefits: An asynchronous set-up fares better with temporary bursts of requests. Central queues allow services to catch up with a reasonable backlog of requests. This is useful both when a lot of requests come in a short span of time or when a service goes down momentarily.
Trade Offs: Higher system complexity; needs mediation for synchronous reads/queries.
Load Balancing
Proxy: a server that sits in front of a group of client machines that intercepts outbound requests (connecting to sites and services online) and then communicates with web servers on behalf of those clients, like a middleman. a.k.a. forward proxy, proxy server, or web proxy.
Reverse Proxy: a server that sits in front of a group of hosts / web servers and forwards client requests to those servers. Same thing as a proxy, but on the server side instead of client side.
Load Balancer: a device that acts as a reverse proxy and distributes network or application traffic across a number of servers. It helps scale horizontally across an ever-increasing number of servers.
Load balancers are generally grouped into two categories: Layer 4 and Layer 7.
Layer 4: Transport Layer - UDP, TCP, SCTP
-
It acts upon data found in network and transport layer protocols (IP, TCP, FTP, UDP). They are mostly the network address translators (NATs) which share the load to the different servers getting translated to by these load balancers.
-
Session persistence can be achieved at the IP address level.
-
No termination for TCP connections.
-
i.e.: AWS Network Load Balancer, Azure Load Balancer, Nginx as TCP and UDP load balancer
-
Layer 7: Session, Presentation, and Application Layers - HTTPS, SMTP, IMAP, FTP, DNS, NNTP
-
It distributes requests based upon data found in application layer protocols such as HTTP. They can further distribute requests based on application-specific data such as HTTP headers, cookies, or data within the application message itself, such as the value of a specific parameter.
-
For the client, the destination IP will be the IP of the load balancer, for the backend server, the source IP will be the IP of the load balancer.
-
The cookie can be used to achieve a sticky session.
-
IP of the client will be kept with the X-Forwarded-For header.
-
To get the HTTP information, the connection is terminated at the load balancer, thus, there will be 2 TCP connections: Client-LB, LB-Backend.
-
i.e. AWS Application Load Balancer, Azure Application Gateway, Nginx as HTTP load balancer
Distribution Strategies: different methods use different algorithms and are best suited for particular situations.
-
Least Connection Method: directs traffic to the server with the fewest active connections. Most useful when there are a large number of persistent connections in the traffic unevenly distributed between the servers.
-
Least Response Time Method: directs traffic to the server with the fewest active connections and the lowest average response time.
-
Round Robin Method: rotates servers by directing traffic to the first available server and then moves that server to the bottom of the queue. Most useful when servers are of equal specification and there are not many persistent connections.
-
IP Hash: the IP address of the client determines which server receives the request.
Caching
Cache: a small memory, fast access local storage where we store frequently accessed data.
Caching: technique of storing copies of frequently used application data in a layer of smaller, faster memory in order to improve data retrieval times, throughput, and compute costs.
Content Delivery Network (CDN): refers to a geographically distributed group of servers which work together to provide fast delivery of Internet content.
-
allows for the quick transfer of assets needed for loading Internet content including HTML pages, javascript files, stylesheets, images, and videos.
-
A properly configured CDN may also help protect websites against some common malicious attacks, such as Distributed Denial of Service (DDOS) attacks.
-
i.e. Amazon Cloudfront, CloudFlare, Google App Engine, jsDelivr
CDN Caching: a CDN caches content (such as images, videos, or webpages) in proxy servers that are located closer to end users than origin servers. Because the servers are closer to the user making the request, a CDN is able to deliver content more quickly.
Redis: an in-memory data store that is most often used as a distributed cache. It offers a variety of efficient data structures designed to allow very fast access to your data. It is used as a caching mechanism in most of the distributed systems.
-
Client-side: Accelerate retrieval of web content from websites through a browser.
-
DNS: Domain to IP Resolution through a DNS server.
-
Server: Accelerate retrieval of web content from web/app servers. i.e. HTTP Cache Headers, CDNs, Reverse Proxies, Web Accelerators, Key/Value Stores, Amazon CloudFront, ElastiCache for Redis, ElastiCache for Memcached, Partner Solutions
Cache Eviction Policy: define a set of rules that decide what data must be removed when the cache is full and a new entry is to be added
-
First In First Out (FIFO): Evicts the first entry in the cache regardless of how many times it was called.
-
Least Recently Used (LRU): Evicts the least recently used items first.
-
Most Recently Used (MRU): Evicts the most recently used items first.
-
Least Frequently Used (LFU): Counts how often an entry was read from cache. Those that are used least often are discarded first.
-
Random Replacement (RR): Randomly selects a candidate item and discards it to make space when necessary.
Consistent Hashing
Consistent Hashing: a distributed hashing scheme that operates independently of the number of servers or objects in a distributed hash table. It powers many high-traffic dynamic websites and web applications.
Uses cases
-
To provide elastic scaling (a term used to describe dynamic adding/removing of servers based on usage load) for cache servers.
-
Scale-out a set of storage nodes like NoSQL databases.
Databases
Database: an organized collection of structured information, or data, typically stored electronically in a computer system usually controlled by a database management system (DBMS).
DBMS: serves as an interface between the database and its end users or programs, allowing users to retrieve, update, and manage how the information is organized and optimized.
Sharding: a method for distributing a single dataset across multiple databases, which can then be stored on multiple machines. This allows for larger datasets to be split into smaller chunks and stored in multiple data nodes, increasing the total storage capacity of the system.
Replication: process of copying data from a central database to one or more databases. The central database is called the publication database because it provides the data for users at other sites. The data in the publication database is copied (replicated) to subscription databases at other locations. All users whether connected to the publisher server (the Publisher) or to a server at one of the remote sites (a Subscriber) see the same data and work on the same records. A Subscriber can be a Subscriber such as a file server or a disconnected Subscriber such as a laptop. The point is to achieve real-time consistency with data for all users, wherever they’re accessing the data from.
Indexing: a pointer to data in a table used in the background of a database to speed up querying. Indexes power queries by providing a method to quickly lookup the requested data.
SQL
Relational Database: stores and provides access to data points that are related to one another. It is organized as a set of tables with columns and rows.
Structured Query Language (SQL): used by nearly all relational databases to query, manipulate, and define data, and to provide access control.
Benefits: faster query processing, a standard easy to learn query language, large user community
Trade Offs: high cost of ownership, dependent on tables, vulnerabilities like SQL injection attacks
NoSQL
NoSQL: allows unstructured and semi-structured data to be stored and manipulated. a.k.a. “non-SQL” or “non-relational”
Document databases store data in documents similar to JSON (JavaScript Object Notation) objects. Each document contains pairs of fields and values. The values can typically be a variety of types including things like strings, numbers, booleans, arrays, or objects.
Key-value databases: are a simpler type of database where each item contains keys and values.
Wide-column stores store data in tables, rows, and dynamic columns.
Graph databases store data in nodes and edges. Nodes typically store information about people, places, and things, while edges store information about the relationships between the nodes.
Benefits: scale-out architecture built in, store unstructured data, ability to store new data without disrupting the current structure.
-
optimized for queries and not for reducing data duplication. NoSQL databases can be larger than SQL databases
-
no “ACID transaction” support across multiple documents
-
all use cases may not be covered in a single database; i.e. using a graph database for analyzing relationships in your data, yet it may not provide what you need for everyday retrieval of the data
Common interview question: How would you design xyz? (things that already exist)
- Facebook's news feed
- Google Drive
- TinyUrl
- WhatsApp
- Amazon
- Netflix
A Miscellany of Advice
Ask clarifying questions. Collect the information you need to ensure that you give the best possible answer to what the interviewer is gauging for. It also shows that you have an understanding of the requirements of the system, and based on those requirements, how you are going to solve the problem.
- what features do we want to focus on
- how many users are we looking to support
- what kind of data are we looking to cache
- Do we want to discuss the end-to-end experience or just the API?
- What clients do we like to support (mobile, web, etc.)?
- Do we require authentication? Analytics? Integrating with existing systems?
- What is the expected read-to-write ratio?
- How many concurrent requests should we expect?
- What’s the average expected response time?
- What’s the limit of the data we allow users to provide?
Don’t immediately go in-depth. Give a high-level overview of the entire system. Steer the conversion and only go in-depth for topics that you know inside and out.
Main Focus: Explain why you are making a decision. What are the benefits? What were the tradeoffs that you were willing to make